Drone Forestry
In the Summer of 2025 I spent a few months contributing to open-source code for the Open Forest Observatory (OFO) where a friend works, which is part of the larger FOCAL Lab at UC Davis. The OFO is a really neat program, they have 1600+ (and growing) drone collections of forests publically available, as well as software tools to process those drone images and turn them into georeferenced forest meshes, orthomosaics, and tree detections. One of the particular strengths of OFO is using structure-from-motion (SfM) tools to turn a collection of drone images into a series of useful outputs. For each drone flight you can calculate:
- Georeferenced camera positions
- A point cloud model of the scene
- A mesh model of the scene
The SfM pipeline was very interesting, and it was really a pleasure to work on these high-quality 3D reconstructions to create new functionality instead of starting from scratch.
Camera Distortion Correction
I think one of my most notable contributions to OFO was noticing the effects of camera distortion and then subsequently fixing it. One of the core strengths of OFO is the mesh modeling of forests from overhead drone flights, and a common use case for that mesh model is to segment a tree in an image and project that segmentation onto the mesh. By doing this from multiple images, you can build up a mesh model that has been labeled with individual trees or with tree species information (depending on the segmentation method you run).
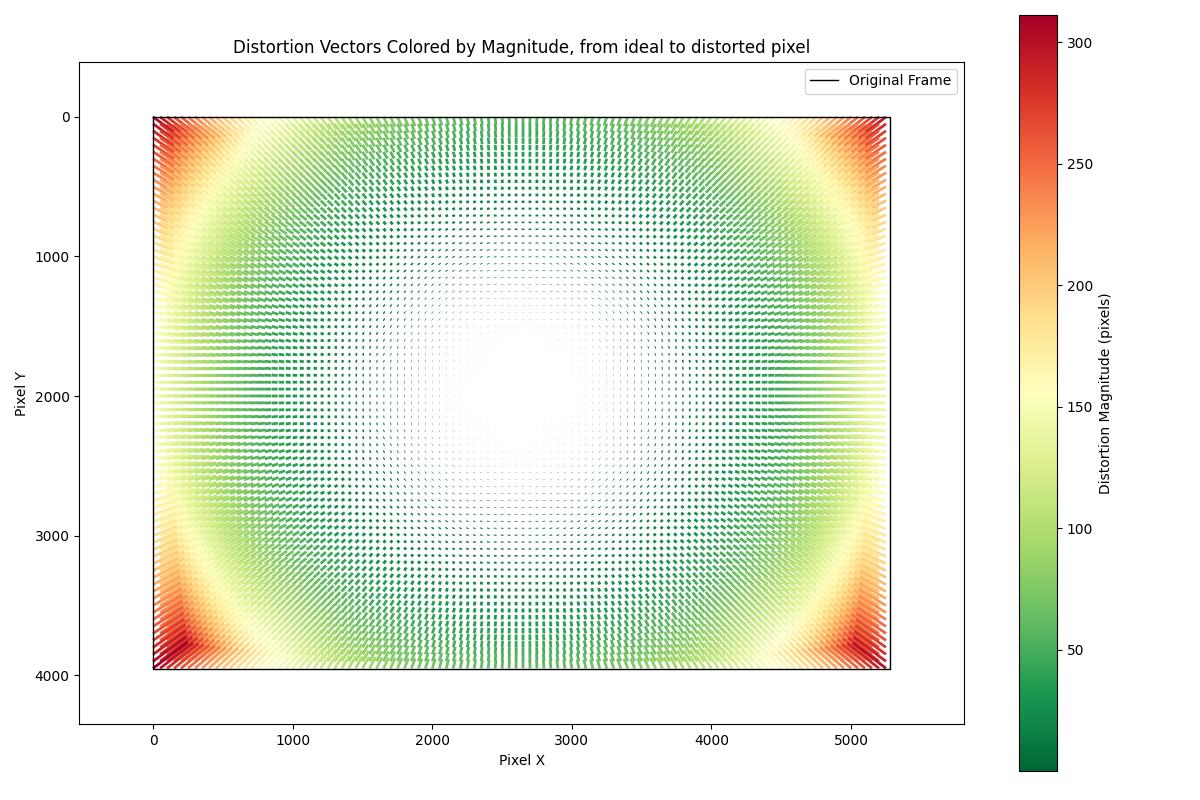
I noticed that in the corners of the images, the projection of the image onto the mesh was significantly off. As shown in the graph, the drone camera had distortion that reached 300 pixels in the corners. This is a pretty significant distortion when you’re trying to label trees that may be only a few meters wide.
Here you can see the effects of distortion when it is not corrected for. You can see the points in the scene shift as the gif cycles between the drone image (more detailed, has a car in the scene) and the rendered mesh. In the corners the differences are particularly extreme, and projections from segmented images will project incorrectly onto the mesh, sometimes entirely missing the intended tree.

As part of the structure-from-motion process that OFO was already using to build the initial model, camera distortion parameters were already being calculated, they just weren’t being used for anything yet. I made a function to warp the drone images so they would align well with the 3D mesh model, essentially creating an image as if the drone had an ideal (undistorted) camera. This seems to work quite well, hopefully it will lead to increased accuracy for the OFO models around the edges of the images.

Equirectangular 360° Footage
In the past OFO has largely worked with over-forest drone images, but they are in the process of starting to explore undercanopy GoPro footage for 3D reconstruction as a complement to the drone data. This was my first time working with 360° equirectangular images, and I really enjoyed them! It’s a very neat data capture method, very flexible. When an image is saved in an equirectangular format it is very specifically warped so that the pixel value (from 0 to image width or 0 to image height) is directly mapped to an angle (-π to π horizontally, or -π/2 to π/2 vertically). This means you can directly and simply sample image rays in whatever format you want, allowing synthetic images to be taken in any orientation or aspect ratio. This is why in the GoPro marketing they say “pick the best angles later” and “you’ll have the flexibility to crop, zoom and reframe” and “add pro-level motion with effects like spin, flip, roll, wobble”. All of these are just resampling the 360° data after the fact.
There may be downsides to 360° footage in terms of resolution and stitching artifacts, but overall I’ve really enjoyed working with 360° data and I think the full area capture is very worthwhile, especially while doing 3D reconstruction. I think of it like a mouse on a mousepad. When you’re doing structure from motion on a forward facing camera a single large movement like an operator spin could lose all of your tracking points, but when you have pixels capturing vertically it makes it much harder to lose track of your keypoints.

This is an example of a series of snapshots from the equirectangular image above using a simulated camera.

Neural Radiance Fields (NeRF)
As part of exploring undercanopy 3D reconstruction, I compared Neural Radiance Fields for reconstruction against the standard OFO SfM reconstruction pipeline. For a very brief overview, Neural Radiance Field (NeRF) models have blown up in popularity in research since they came out in 2020. They work by training a neural network to represent a 3D scene, enabling realistic new views from angles not in the original images.
Below is a screenshot from one of our undercanopy NeRF reconstructions, but I would highly recommended watching the video the screenshot came from. It’s not perfect, but it’s still shocking to me that this quality of scene reconstruction can be made from ≈100 equirectangular GoPro images. It was not a complicated process to make this video, either. I ran SfM on the GoPro images, imported those SfM-calculated camera positions into nerfstudio, and within about 20 minutes of training had a NeRF model that could produce that video. nerfstudio is an excellent open source repository of NeRF tools, kudos to them.

Semantic Point Classification
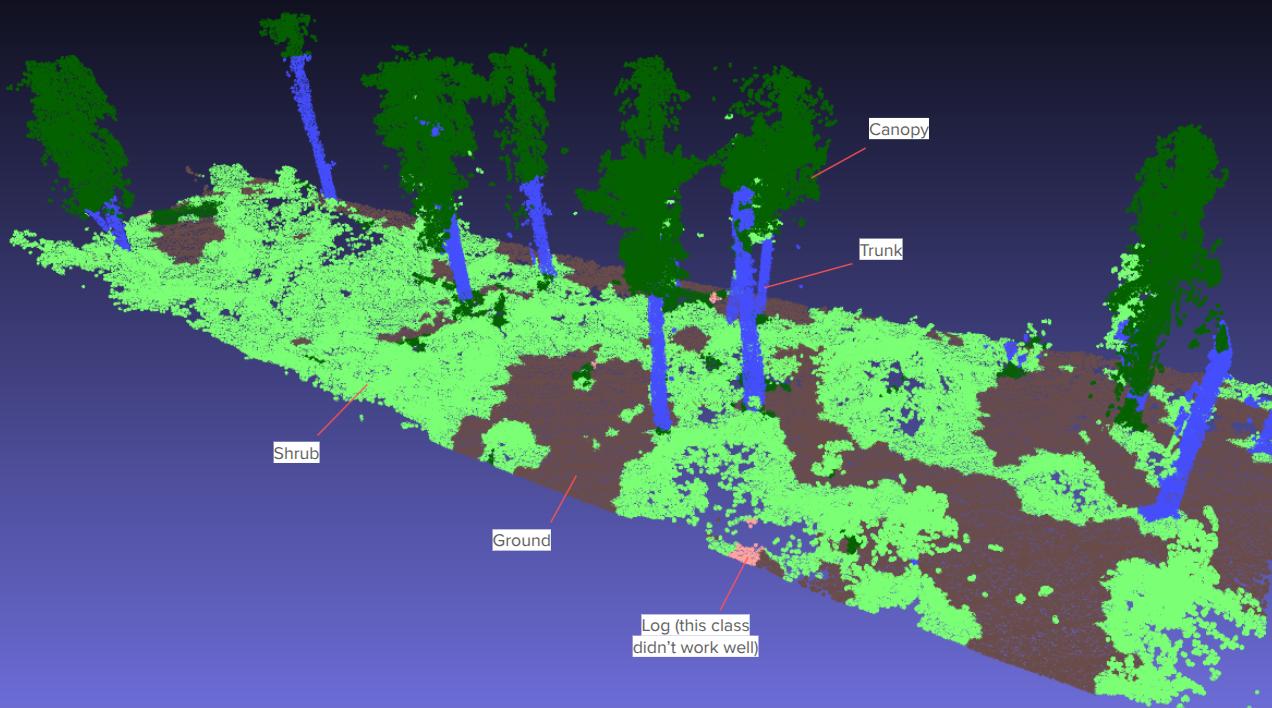
I did a very small-scale prototype of semantic point classification of undercanopy point clouds using handcrafted point features. By taking a very small set of labeled points (points known to be ground, trunk, shrub, etc.) I constructured features for each point that captured the point attributes and attributes of its neighborhood (the local context) and then trained a simple Random Forest model that mapped each feature vector to a classification. Although the training points were only 0.1-0.2% of the points in the scene, the Random Forest model seems to do a pretty good job of classifying the points of the entire scene into classes. I think it’d be worth looking into further to see if a simple point cloud classifier would work across a variety of scenes.
Geometric (Cylinder-based) Trunk Detection
Similarly, I did a small-scale prototype of trunk detection via cylinder fitting to see how well it would work. I first ran a clustering algorithm (DBSCAN) in X and Y on data that had been clipped to a certain height but retained a fair amount of canopy noise. This was to isolate individual trees, and is shown in the first image. Then I ran cylinder finding using RANSAC to attempt to separate out trunk points from canopy (leaves/branches), shown in the second image. As a note there are some short shrubs that are identified as cylinders in the right-side foreground, I ignored these because it would be simple to filter them out with a height requirement.
As a first-pass to identify the obvious trunks I think this could be useful, particularly with some tweaks to the process to allow for curvature or to do a final fit with an expanded acceptability cutoff. In addition, it would be useful to modify the RANSAC approach to split apart trunks that are close and get clustered together. This could potentially be done by looking at how well supported a second proposed cylinder would be. In general this sort of classical geometry-only approach looks promising.


Multi-view Tree Detection
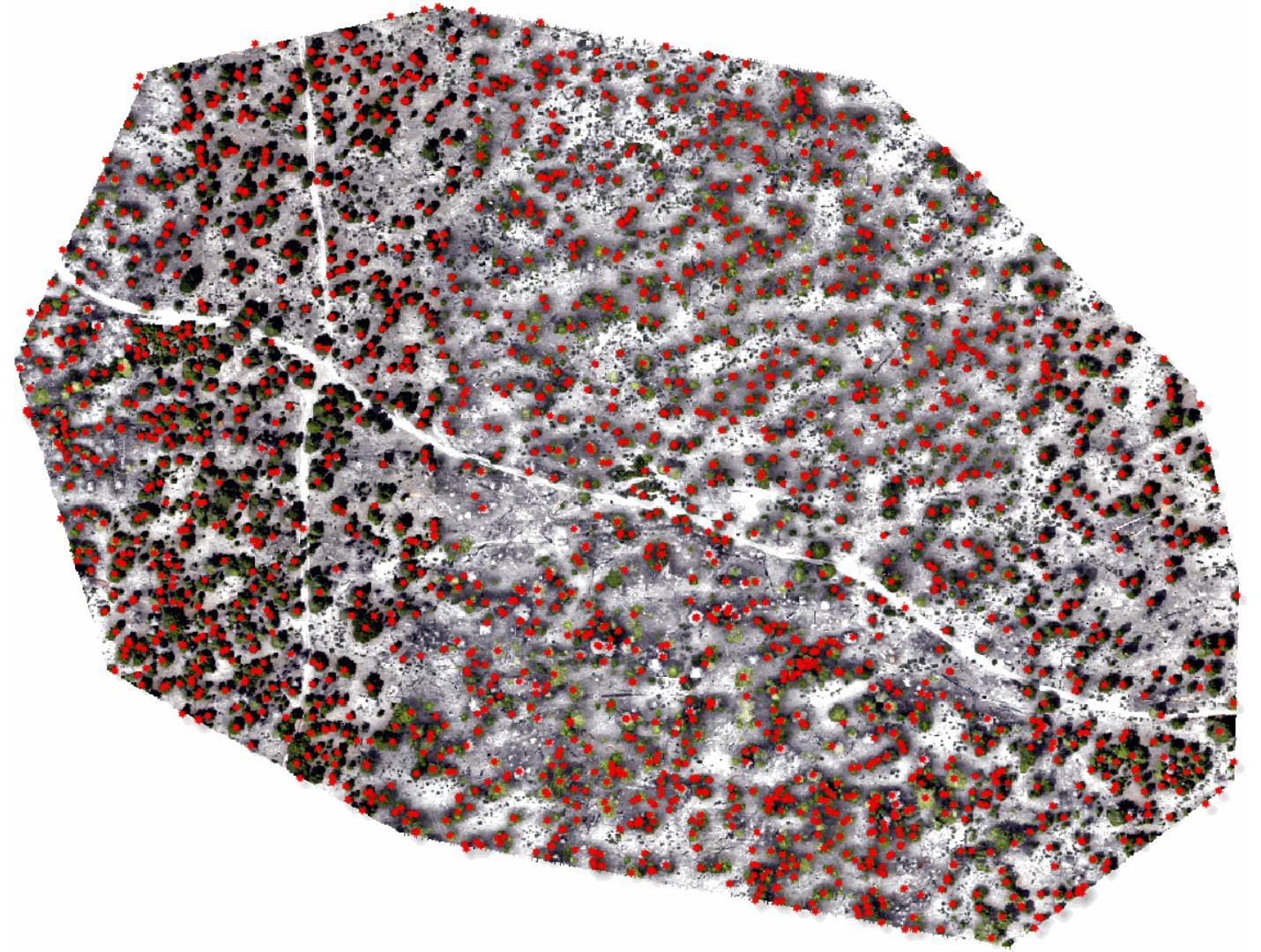
The first project that I worked on for OFO was a multi-view approach for detecting trees. Instance segmentation of trees was run on individual images, then each segment was turned into a “ray” out from the camera and through the center of the segmented area. By looking at community clusters in the graph of ray-ray intersection distances, you could try to group rays together that came very close to each other (hypothetically, these rays have converged on a single tree). You can see the rays in the first image below, they’re represented by small triangular extrusions. Note that the rays are clipped to be within a reasonable height envelope before clustering, this greatly increases the usefulness of the resulting clusters.
It may be possible to make this work with more thought, but I was worried that on denser forests even small segmentation errors would be significant on the scale of the trees those segmentations are being projected onto, so we moved onto other projects.

This is an example of the multi-view detections of trees projected onto a georeferenced orthomosaic.